tibble [19,200 × 60] (S3: tbl_df/tbl/data.frame)
$ UBIGEO : num [1:19200] 150143 150143 150143 150143 150143 ...
$ year : num [1:19200] 2019 2019 2019 2019 2019 ...
$ id : num [1:19200] 19200 19199 19198 19197 19196 ...
$ petition : num [1:19200] 0 0 0 0 0 0 0 0 0 0 ...
$ mass_media_complaining : num [1:19200] 0 0 0 0 0 0 0 0 0 0 ...
$ neighbourhood_org : num [1:19200] 0 0 0 0 0 0 0 0 0 0 ...
$ elected_position : num [1:19200] 0 0 0 0 0 0 0 0 0 0 ...
$ volunteering : num [1:19200] 0 0 0 0 0 0 0 0 0 0 ...
$ participatory_budget : num [1:19200] 0 0 0 0 0 0 0 0 0 0 ...
$ membership : num [1:19200] 0 0 0 0 0 0 0 0 0 0 ...
$ demonstrating : num [1:19200] 0 0 0 0 0 0 0 0 0 0 ...
$ online_groups : num [1:19200] 0 0 0 0 0 0 0 0 0 0 ...
$ social_media_complaining: num [1:19200] 0 0 0 0 0 0 0 0 0 0 ...
$ community_project : num [1:19200] 0 0 0 0 0 0 0 0 0 0 ...
$ female : num [1:19200] 1 1 1 0 1 0 0 0 1 1 ...
$ age : num [1:19200] 18 23 33 47 41 50 81 67 33 42 ...
$ district : num [1:19200] 150143 150143 150143 150143 150143 ...
$ borough : chr [1:19200] "Lima Sur" "Lima Sur" "Lima Sur" "Lima Sur" ...
$ ses_factor : Factor w/ 5 levels "A","B","C","D",..: 2 4 4 3 4 2 3 4 2 3 ...
$ ses_rev : num [1:19200] 4 2 2 3 2 4 3 2 4 3 ...
$ lowered : num [1:19200] 0 0 0 0 0 0 0 0 0 0 ...
$ old_timer : num [1:19200] 1 1 1 1 0 1 1 1 1 1 ...
$ safety_lima : num [1:19200] 2 0 0 1 0 3 2 0 0 0 ...
$ workstudy_outside : num [1:19200] 1 0 0 1 1 0 0 1 1 0 ...
$ works_home : num [1:19200] 0 1 1 0 0 0 0 0 0 1 ...
$ works_not : num [1:19200] 0 0 0 0 0 1 1 0 0 0 ...
$ walk_bike : num [1:19200] 0 0 0 0 1 0 0 0 0 0 ...
$ transit : num [1:19200] 1 0 0 1 0 0 0 1 1 0 ...
$ drive_or_taxi : num [1:19200] 0 0 0 0 0 0 0 0 0 0 ...
$ commute_min : num [1:19200] 30 NA NA 90 10 NA NA 90 65 NA ...
$ safety_hood : num [1:19200] 3 0 2 0 3 3 2 1 0 0 ...
$ victimization : num [1:19200] 0 0 0 0 1 0 0 1 1 1 ...
$ fences_supporter : num [1:19200] NA NA NA NA NA NA NA NA NA NA ...
$ children_under15 : num [1:19200] NA NA NA NA NA NA NA NA NA NA ...
$ trust_neighbours : num [1:19200] NA NA NA NA NA NA NA NA NA NA ...
$ civiceng_core : num [1:19200] 0 0 0 0 0 0 0 0 0 0 ...
$ civiceng_allvars : num [1:19200] 0 0 0 0 0 0 0 0 0 0 ...
$ DISTRITO : chr [1:19200] "VILLA MARIA DEL TRIUNFO" "VILLA MARIA DEL TRIUNFO" "VILLA MARIA DEL TRIUNFO" "VILLA MARIA DEL TRIUNFO" ...
$ HOGNSEA17 : num [1:19200] 37 37 37 37 37 37 37 37 37 37 ...
$ HOGNSEB17 : num [1:19200] 7370 7370 7370 7370 7370 7370 7370 7370 7370 7370 ...
$ HOGNSEC17 : num [1:19200] 35222 35222 35222 35222 35222 ...
$ HOGNSED17 : num [1:19200] 42553 42553 42553 42553 42553 ...
$ HOGNSEE17 : num [1:19200] 15228 15228 15228 15228 15228 ...
$ NSE_PREDOM : chr [1:19200] "D" "D" "D" "D" ...
$ ls : num [1:19200] 0.159 0.159 0.159 0.159 0.159 ...
$ p : num [1:19200] 0.0412 0.0412 0.0412 0.0412 0.0412 ...
$ ls_cat : chr [1:19200] "medium" "medium" "medium" "medium" ...
$ circuity_avg_mean : num [1:19200] 1.07 1.07 1.07 1.07 1.07 ...
$ intersection_mean : num [1:19200] 206 206 206 206 206 ...
$ barriers_00_mean : num [1:19200] 5.09 5.09 5.09 5.09 5.09 ...
$ barriers_01_mean : num [1:19200] 12.7 12.7 12.7 12.7 12.7 ...
$ barriers_03_mean : num [1:19200] 13.2 13.2 13.2 13.2 13.2 ...
$ barriers_05_mean : num [1:19200] 15.8 15.8 15.8 15.8 15.8 ...
$ barriers_10_mean : num [1:19200] 39.1 39.1 39.1 39.1 39.1 ...
$ dist_node_mean : num [1:19200] 38.9 38.9 38.9 38.9 38.9 ...
$ pre1975_prop : num [1:19200] 0.895 0.895 0.895 0.895 0.895 ...
$ pre1990_prop : num [1:19200] 0.957 0.957 0.957 0.957 0.957 ...
$ change19752020_prop : num [1:19200] 0.102 0.102 0.102 0.102 0.102 ...
$ change19902020_prop : num [1:19200] 0.0396 0.0396 0.0396 0.0396 0.0396 ...
$ year_factor : Factor w/ 10 levels "2010","2011",..: 10 10 10 10 10 10 10 10 10 10 ...
Exploring dependent variables
The data includes 19200 observations for ten years of the Lima Cómo Vamos survey. There are 59 variables besides the ID, 23 of them are contextual. The types of analyses are restricted due to data availability for specific years. For instance, my main outcomes of interest are civic engagement and trust in neighbours. The survey includes the former in every year, but the latter only for the 2010-2014 period.
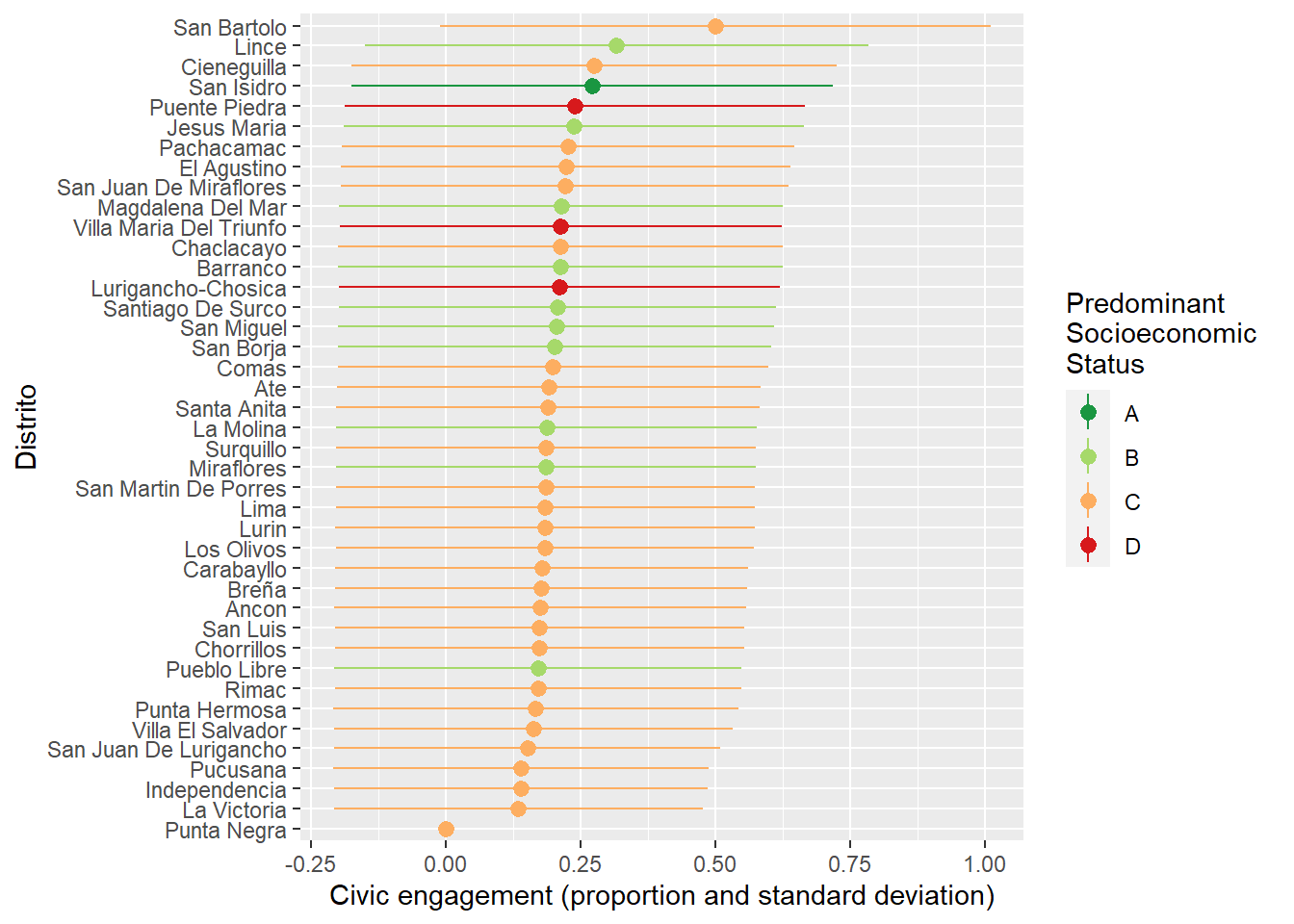
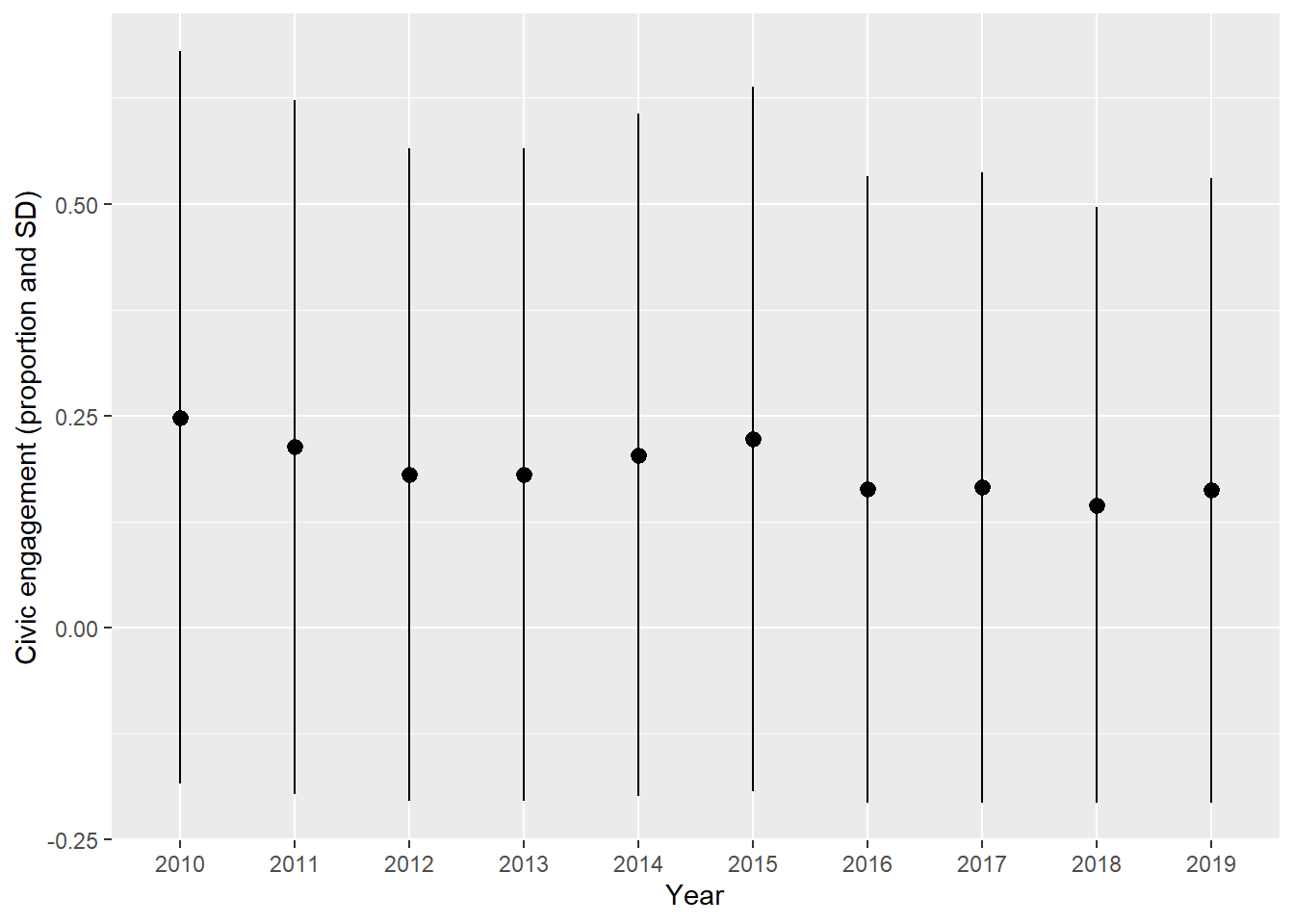
I measure civic engagement through a series of questions about participation in collective action, from signing petitions to attending participatory budget meetings. I use a summary indicator of having partaking in any of them as civiceng_core (dummy) for those items present in all years. The proportion of respondents that have partaken is 0.19 (sd =0.39), but this varies a lot by district and year (see Figure 1 and Figure 2).
Code
lcv1019_ctx |>mutate(DISTRITO =str_to_title(DISTRITO)) |>group_by(UBIGEO, DISTRITO) |>summarize(ses_predom =unique(NSE_PREDOM, na.rm =TRUE),mean_ce =mean(civiceng_core, na.rm =TRUE),sd_ce =sd(civiceng_core, na.rm =TRUE)) |>ggplot(aes(x =reorder(DISTRITO, mean_ce), y = mean_ce,group = ses_predom, color = ses_predom)) +geom_pointrange(aes(ymin = mean_ce-sd_ce, ymax = mean_ce+sd_ce)) +scale_color_brewer(palette ='RdYlGn', direction =-1) +labs(x ='Distrito',y ='Civic engagement (proportion and standard deviation)',color ='Predominant \nSocioeconomic \nStatus') +coord_flip()
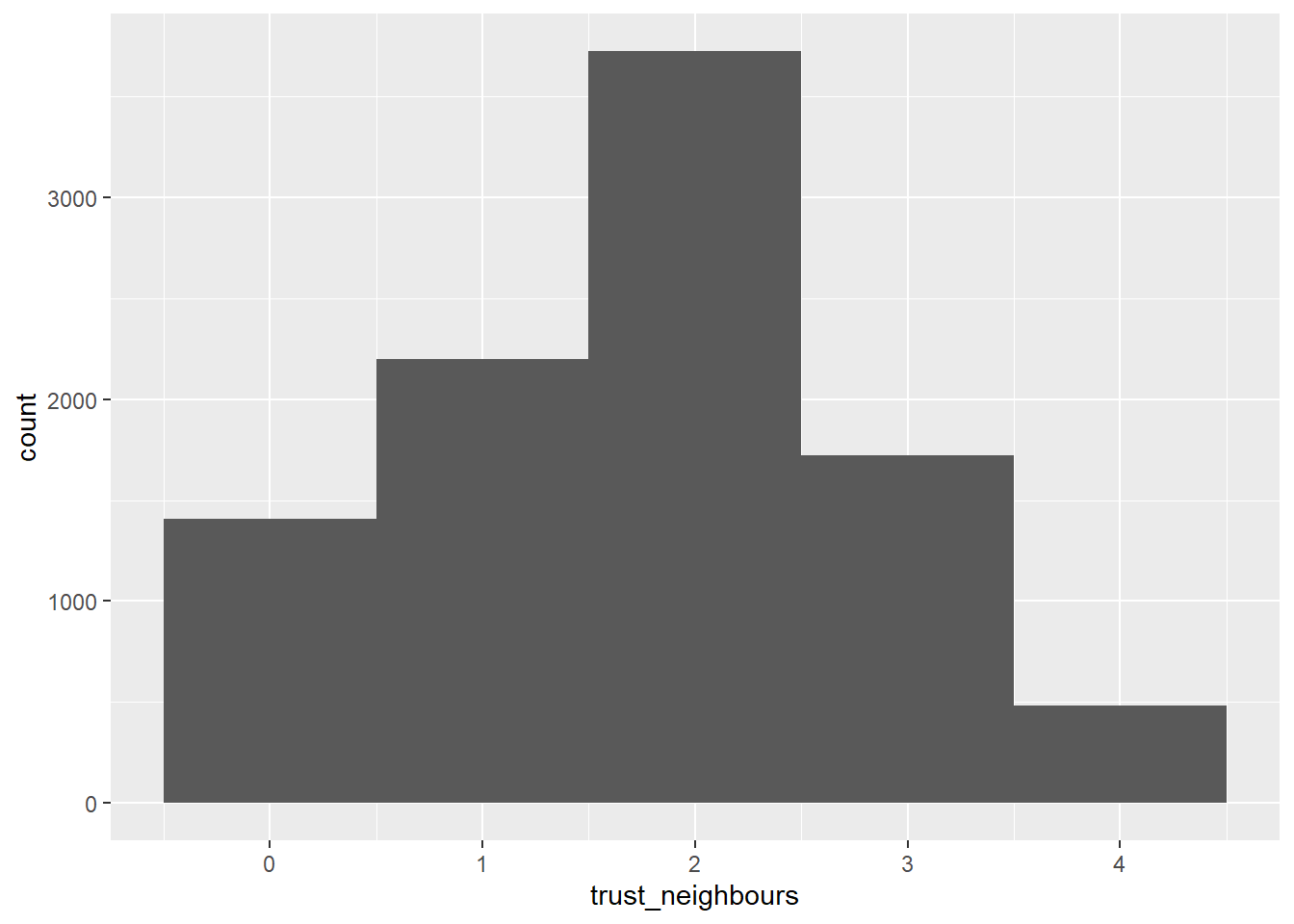
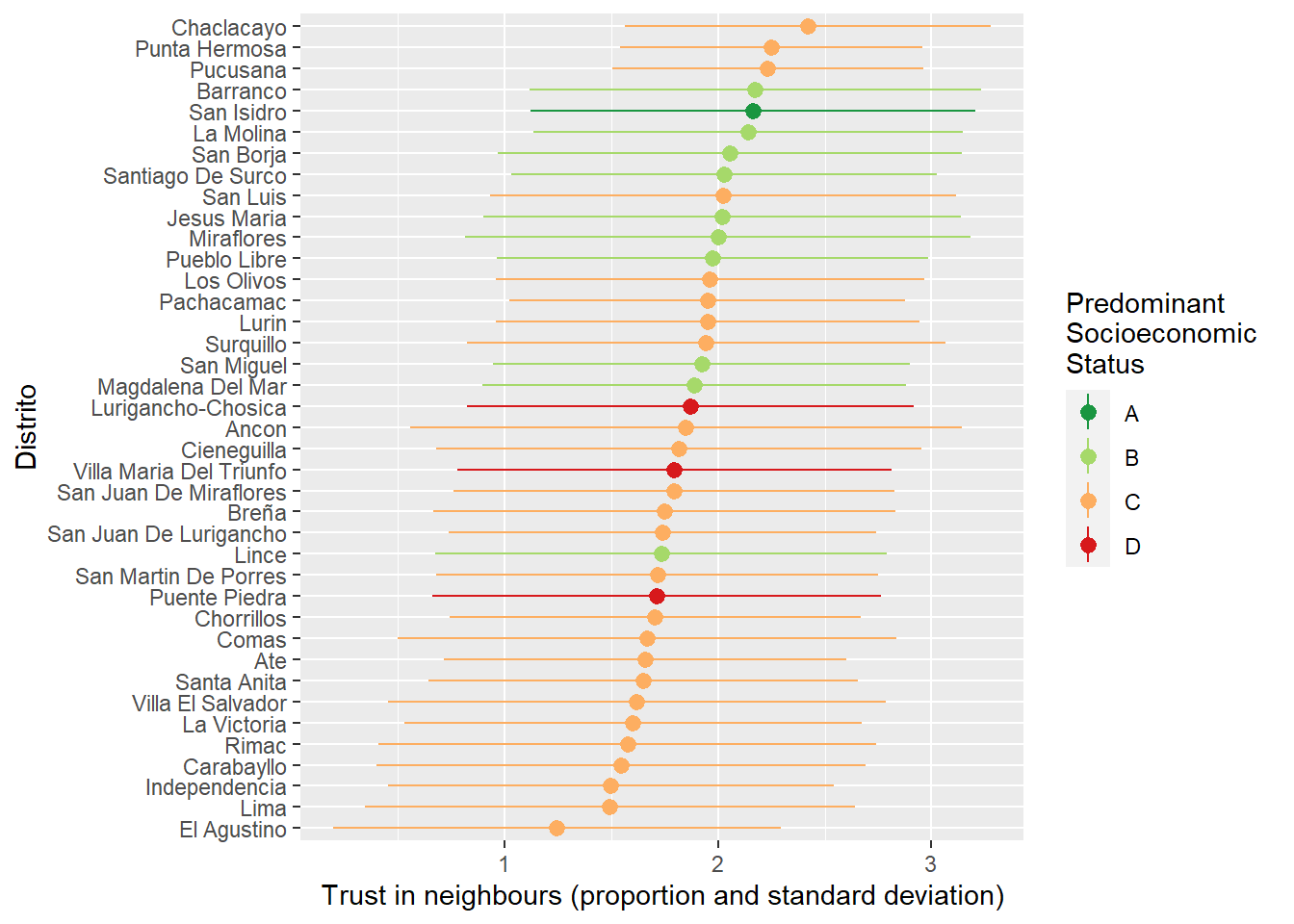
A version of the restricted dataset is for the years 2010-2014. These years include a question about trust in neighbours. The distribution of these responses is approximately normal (see Figure 3). tbl-trust shows see the distribution of responses by year, while Figure 4 plots the means and standard deviations by district (colour indicates the predominant socioeconomic status of the district, A being the highest).
Code
temp =filter(lcv1019_ctx, year <2015)ggplot(temp, aes(trust_neighbours)) +geom_histogram(binwidth =1)
lcv1019_ctx |>filter(year <2015) |>mutate(DISTRITO =str_to_title(DISTRITO)) |>group_by(UBIGEO, DISTRITO) |>summarize(ses_predom =unique(NSE_PREDOM, na.rm =TRUE),mean_trust =mean(trust_neighbours, na.rm =TRUE),sd_trust =sd(trust_neighbours, na.rm =TRUE)) |>ggplot(aes(x =reorder(DISTRITO, mean_trust), y = mean_trust,group = ses_predom, color = ses_predom)) +geom_pointrange(aes(ymin = mean_trust-sd_trust,ymax = mean_trust+sd_trust)) +scale_color_brewer(palette ='RdYlGn', direction =-1) +labs(x ='Distrito',y ='Trust in neighbours (proportion and standard deviation)',color ='Predominant \nSocioeconomic \nStatus') +coord_flip()
Figure 4: Trust in neighbours by district
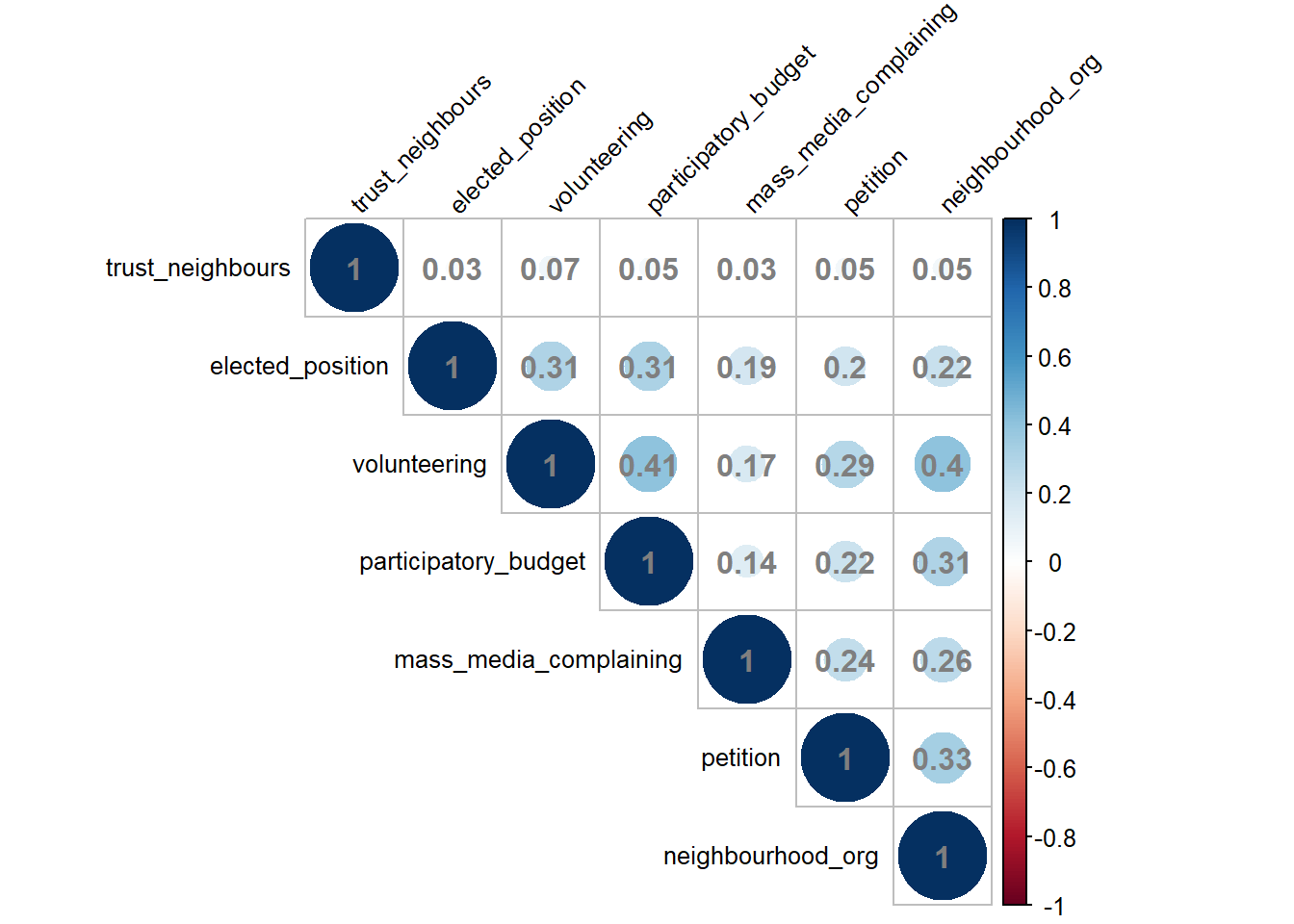
In Figure 5 we can see that trust is not associated with most of the civic engagement variables.
Code
dat =filter(lcv1019_ctx, year <2015) |>select(petition:participatory_budget, trust_neighbours)vmat =PairApply(dat, CramerV) # Cramer's V instead of Pearson for precisioncorrplot(vmat,type ='upper',order ='hclust',addCoef.col ='grey50',tl.col ='black',tl.srt =45,tl.cex =0.8)
Figure 5: Association matrix of potential dependent variables (Cramer’s V)
Upon this exploration, and considering that I have aggregated data at the district level, I model civic engagement using multilevel logistic regression and trust in neighbours with multilevel linear regression.
Exploring independent variables
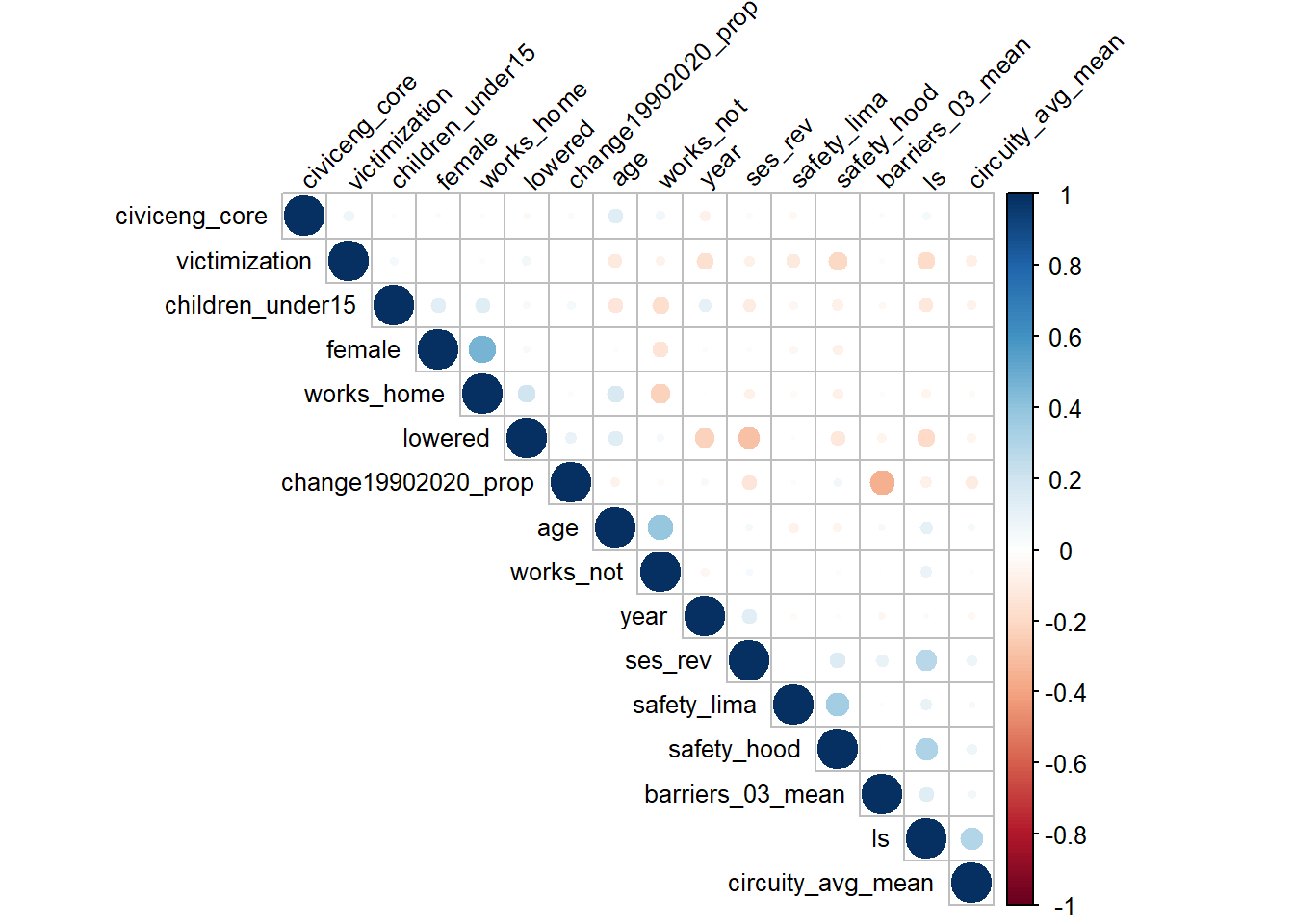
The list of independent variables is contingent on the years for the analysis. In Figure 6 I show the association between candidates for independent variables across all models. Some of them will be useful for just one of the dependent variables.
While the ICC is low, it is the only available level of geographic aggregation to match the spatial data.
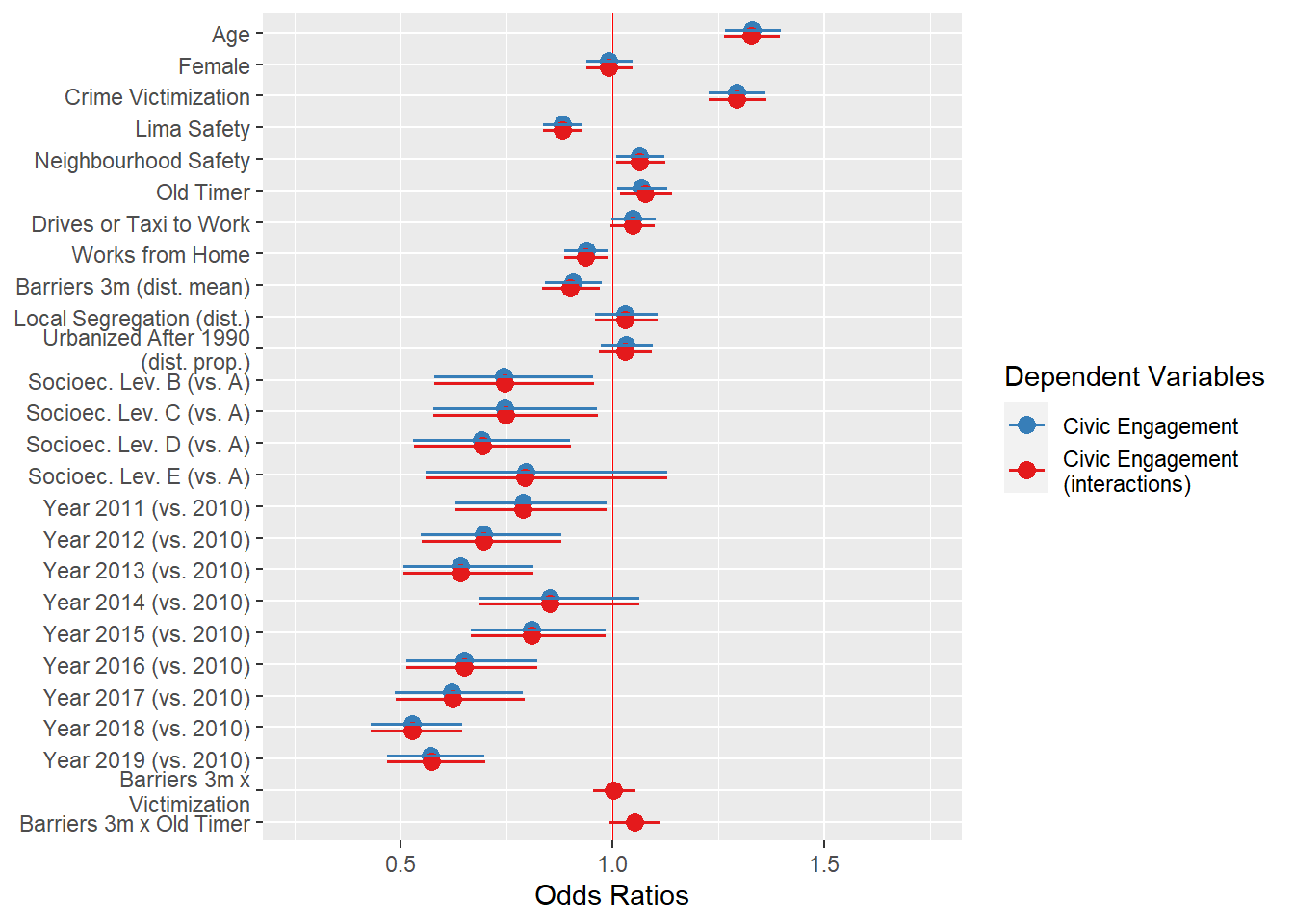
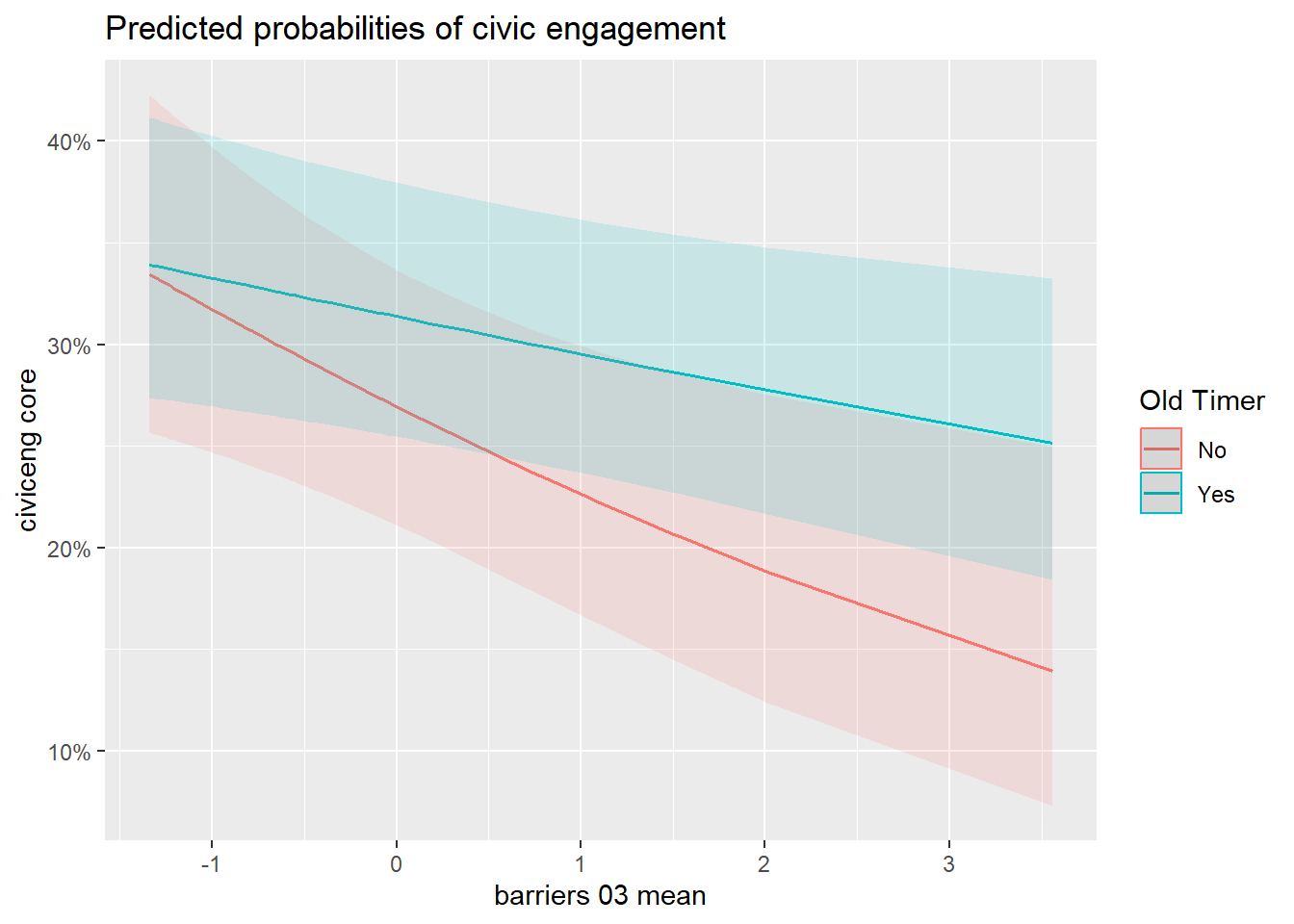
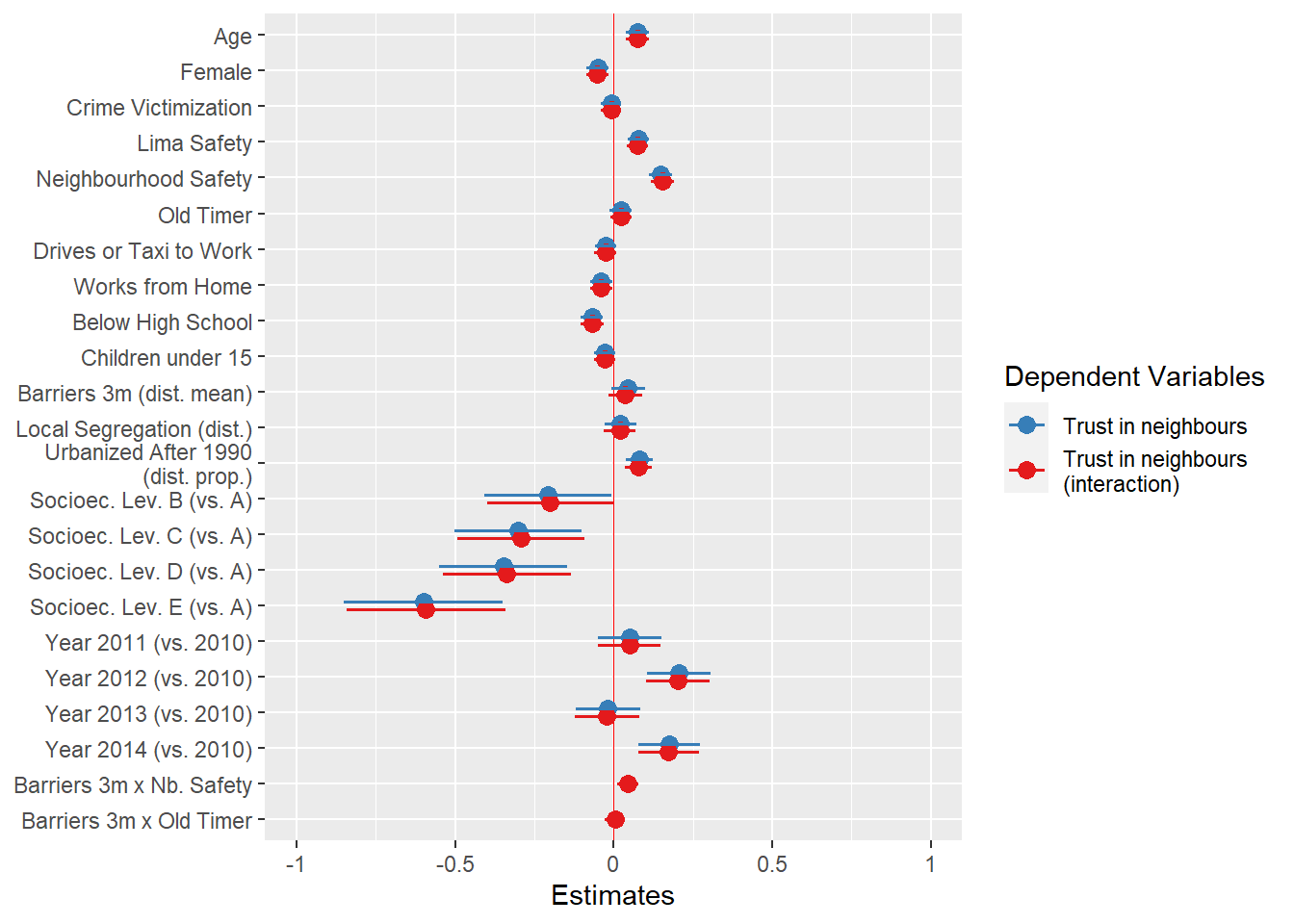
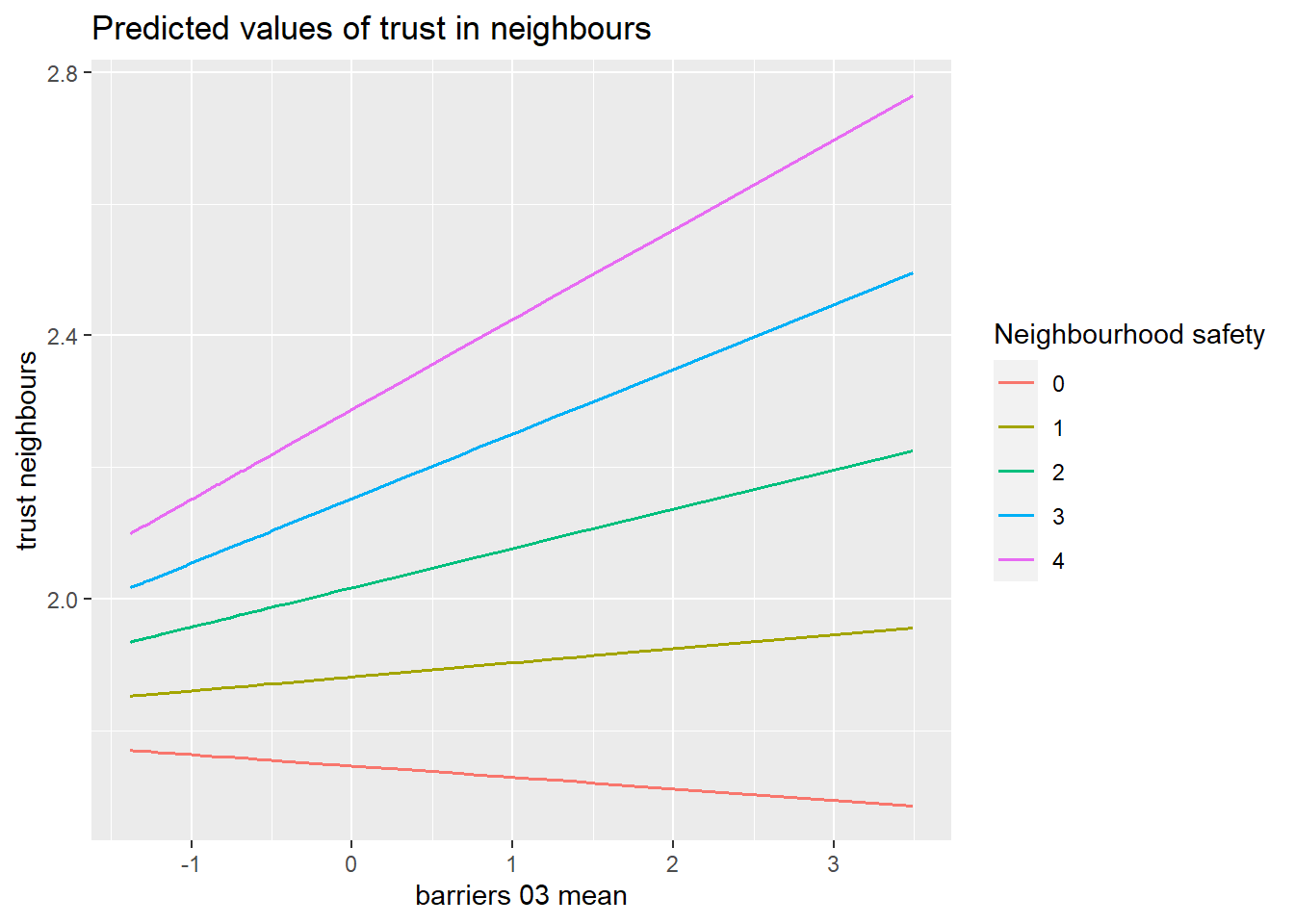
Preliminary models below. I still need to consider ways to organize these models. I could plot all models together for different buffers of barriers, or I could just choose one. They don’t seem to add too much difference and effect sizes are small. Also, consider a way to present models with interaction terms.
The results above use only the district-level average of barriers at 3km buffer as independent variable of interest and not all other buffer levels. The reason is that models do not differ that much from one another.
Trust in neighbours models
The next variable to model is trust in neighbours. First, I fit an intercept only model to calculate the intra-class correlation (ICC) (Table 3).
The ICC is low but higher than the one for civic engagement. The within-district variability suggests the effects of built environment features may be higher.