Reading layer `blocks_data' from data source
`C:\Users\Fernando\Dropbox\Projects\Fences_Lima\data\processed\blocks_data.gpkg'
using driver `GPKG'
Simple feature collection with 99685 features and 24 fields
Geometry type: POINT
Dimension: XY
Bounding box: xmin: -77.19496 ymin: -12.49626 xmax: -76.6713 ymax: -11.72791
Geodetic CRS: NAD83
Code
blocks_data =st_drop_geometry(blocks_data_sf)
Exploring data
I am using the data for all Metropolitan Lima and Callao’s residential blocks N=99,685. This selection filters out blocks without socioeconomic data.
Dependent variables
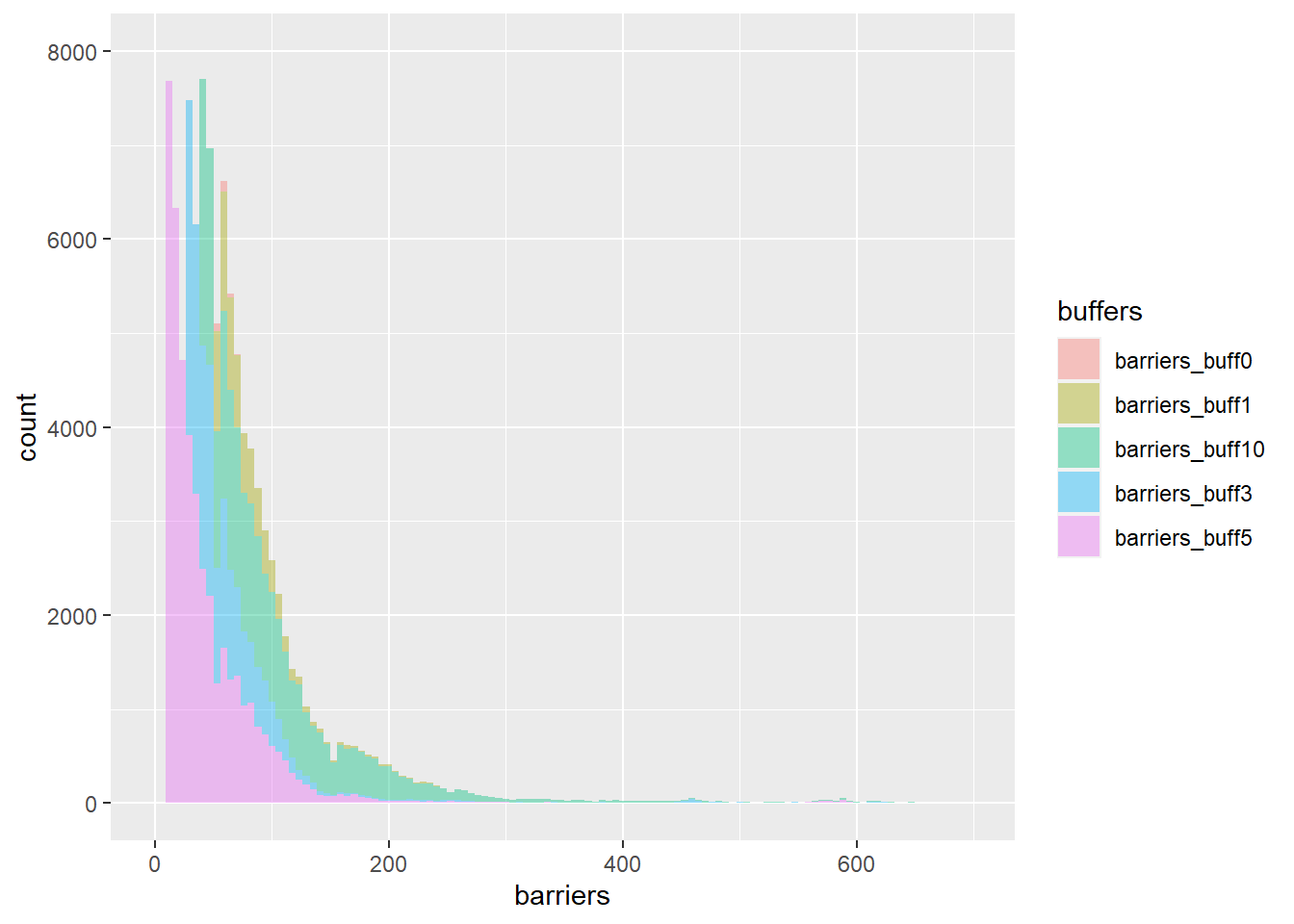
First, I plot the dependent variable candidates. These are the barriers within 1 km network distance from each block in Lima. The distributions are very skewed and some have extremely large counts (>400). Thus, I am removing some of the extreme values from the plot.
These are all count variables. Therefore, it is not recommended to model it using a linear regression. There are also not too many zeroes, which makes the candidates Poisson and negative binomial regressions. Before assessing them, below I show some of the independent variables of interest.
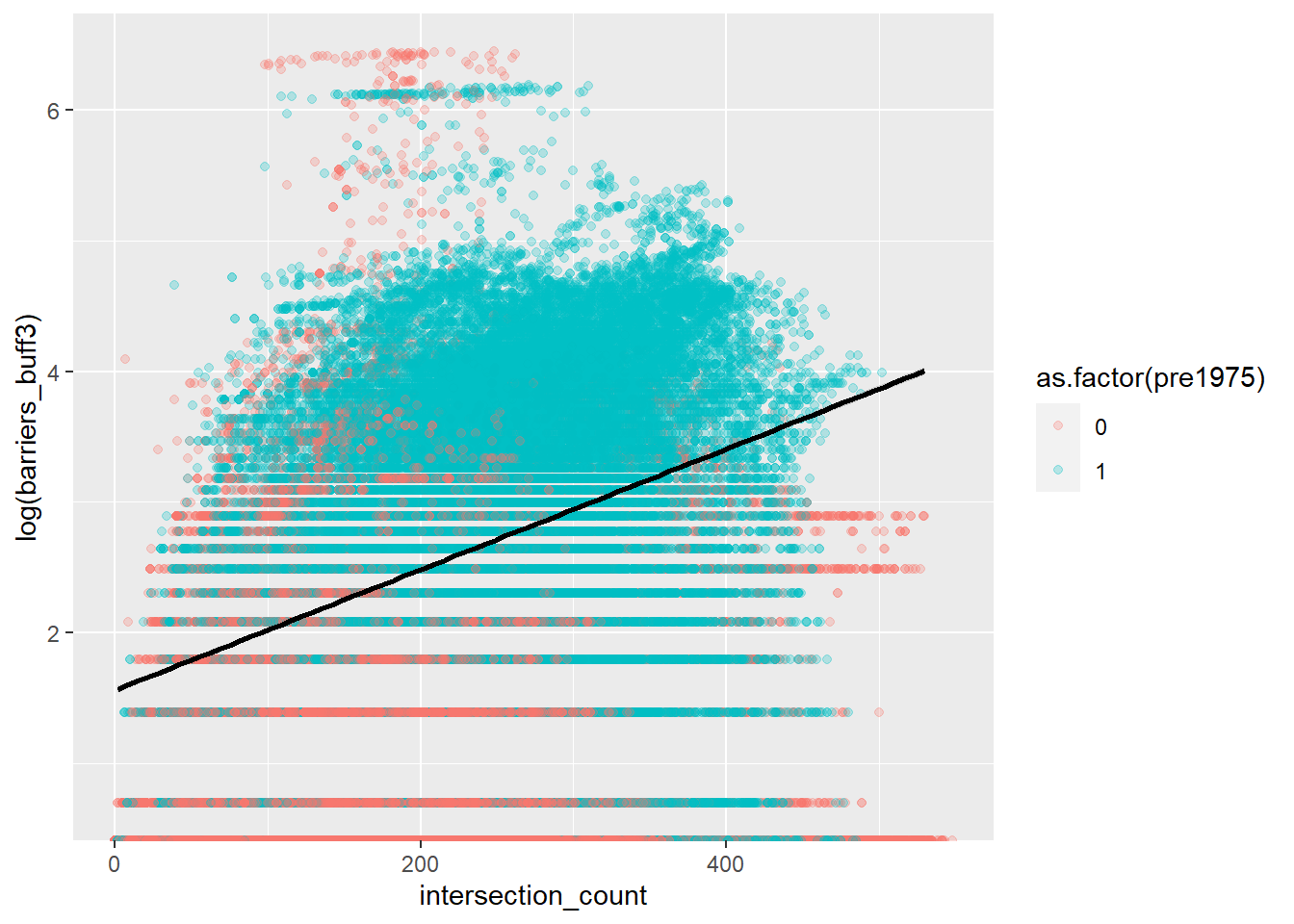
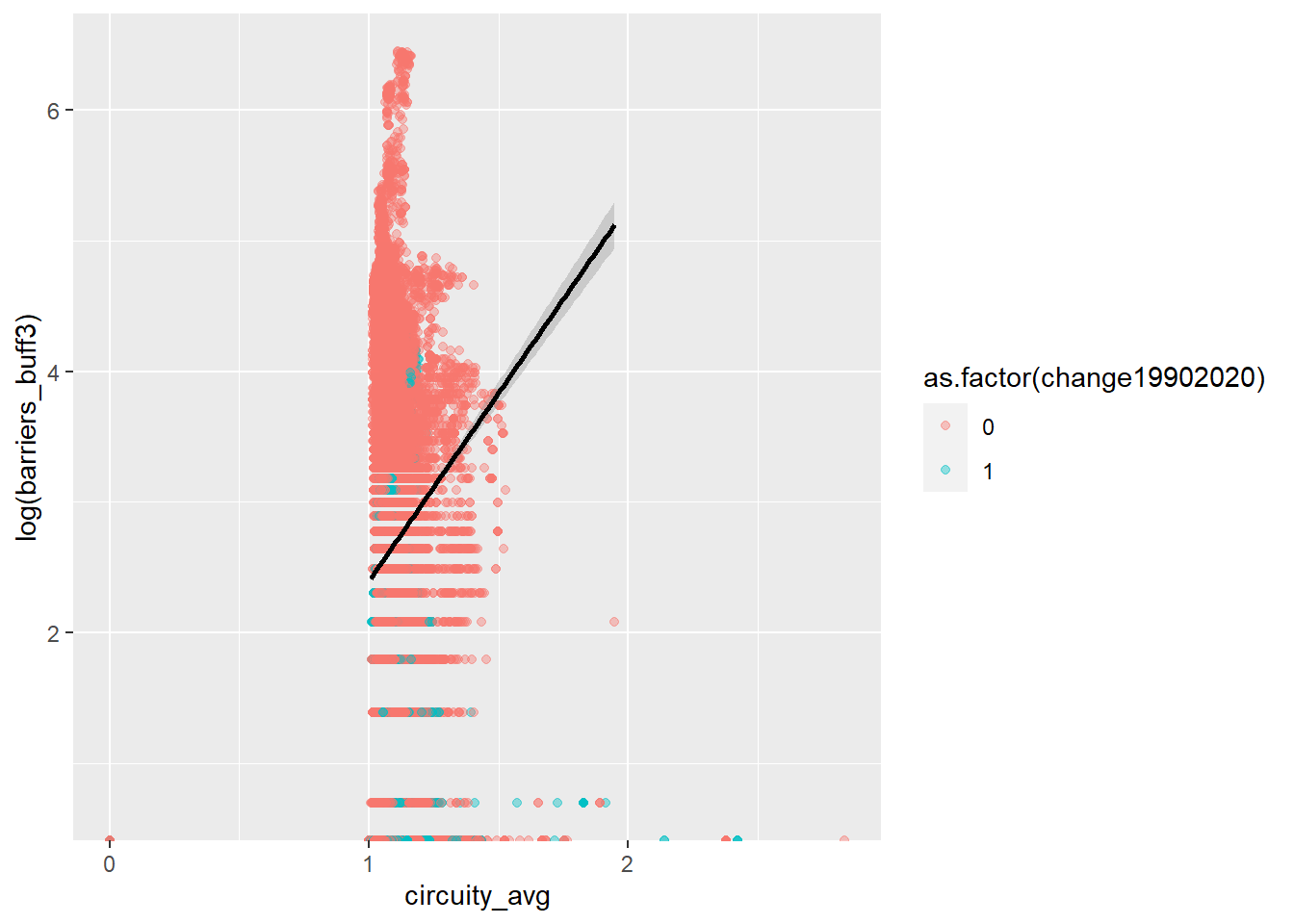
The plots below use barriers_buff3 as the dependent variable for convenience but this is not entirely set. Note that the dependent variable is logged due to its skewed distribution (see above). The logs allow to visualize the relationship with the independent variables before fitting a Poisson or negative binomial regression model.
Conditional means and SD (testing overdispersion)
To decide between a Poisson or a more flexible negative binomial regression, I need to account for potential overdispersion. Overdispersion occurs whenever the variance of \(\lambda_i\) is considerably larger than its mean This is because a Poisson distribution assumes that \(mean=variance\).
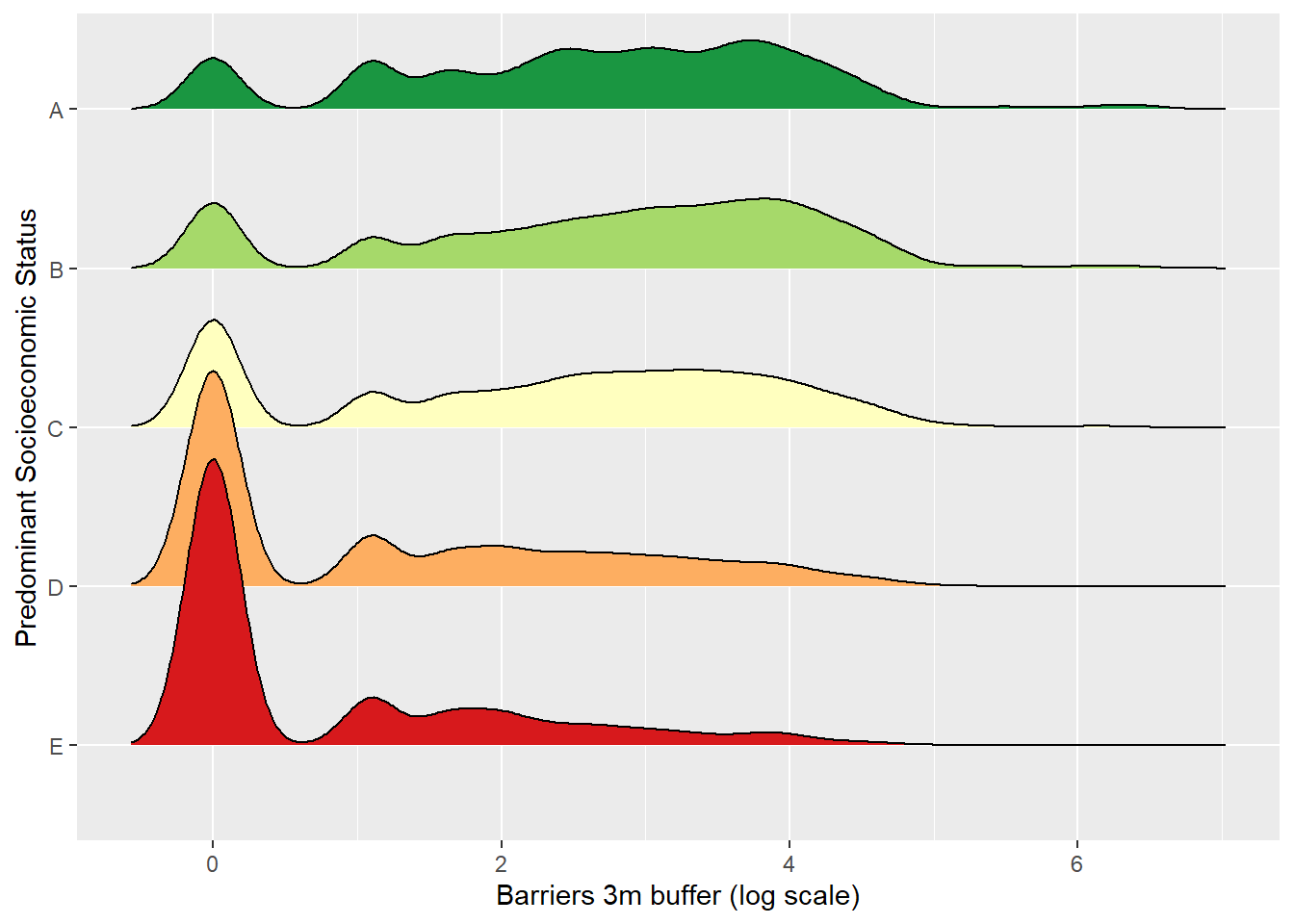
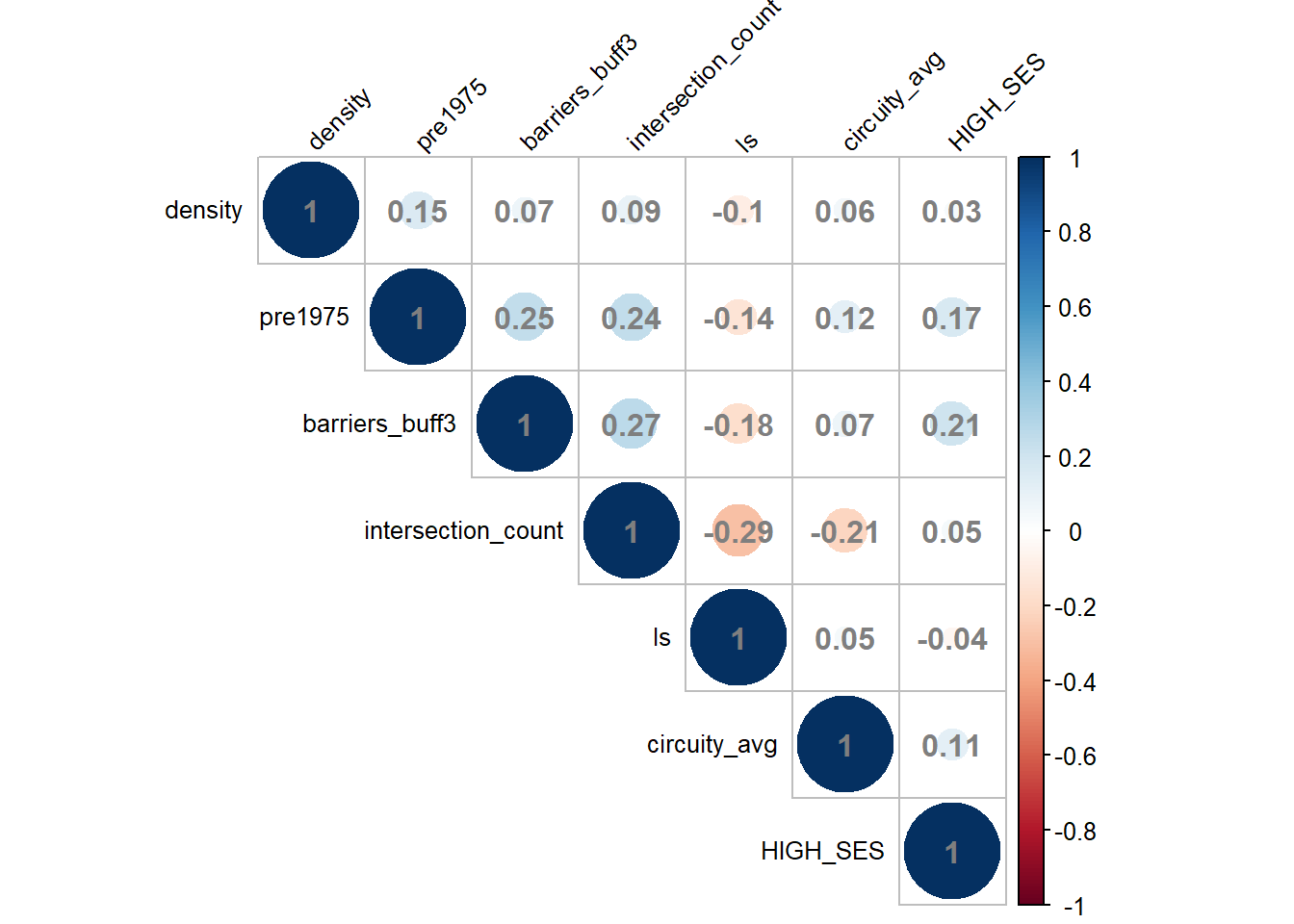
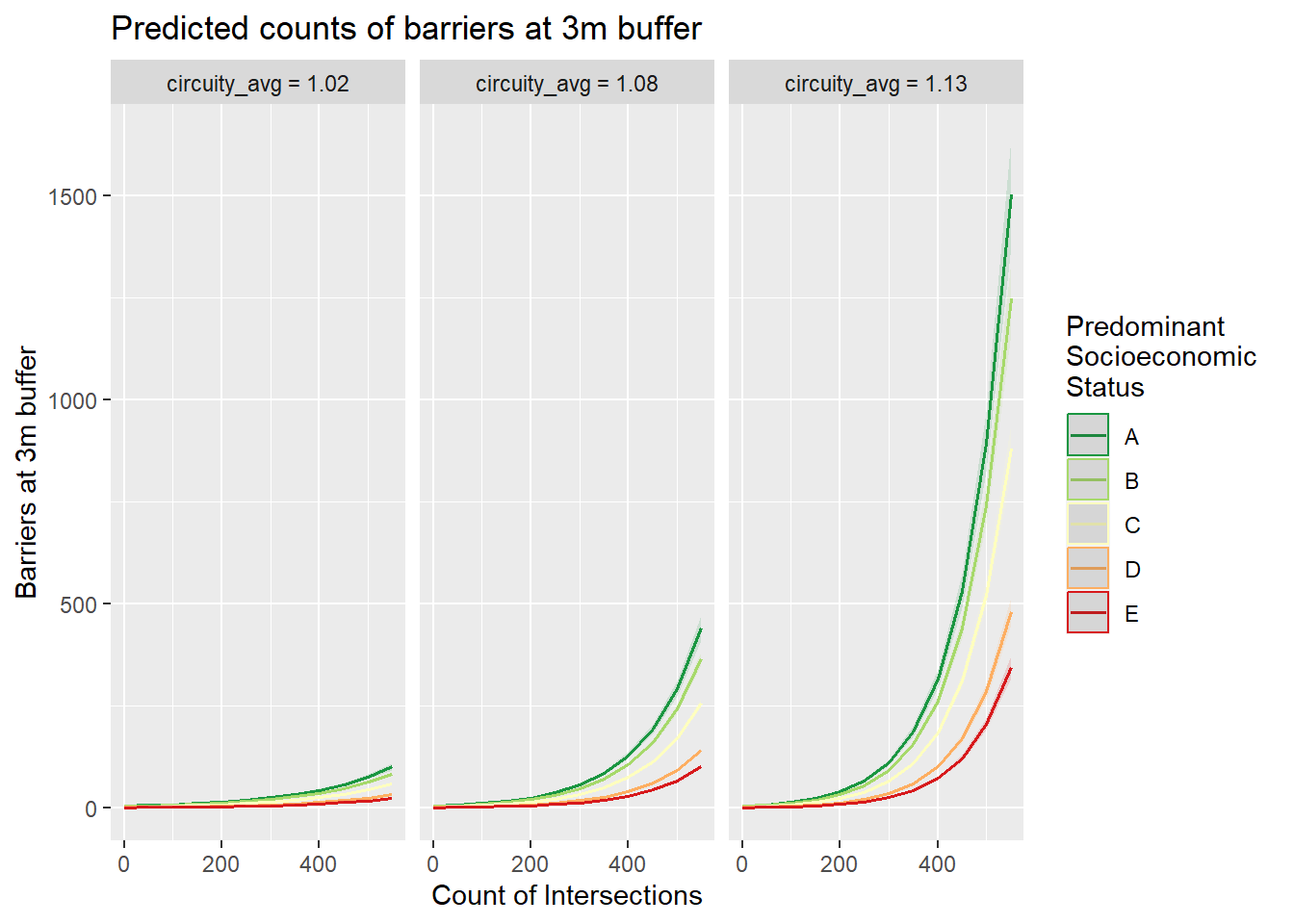
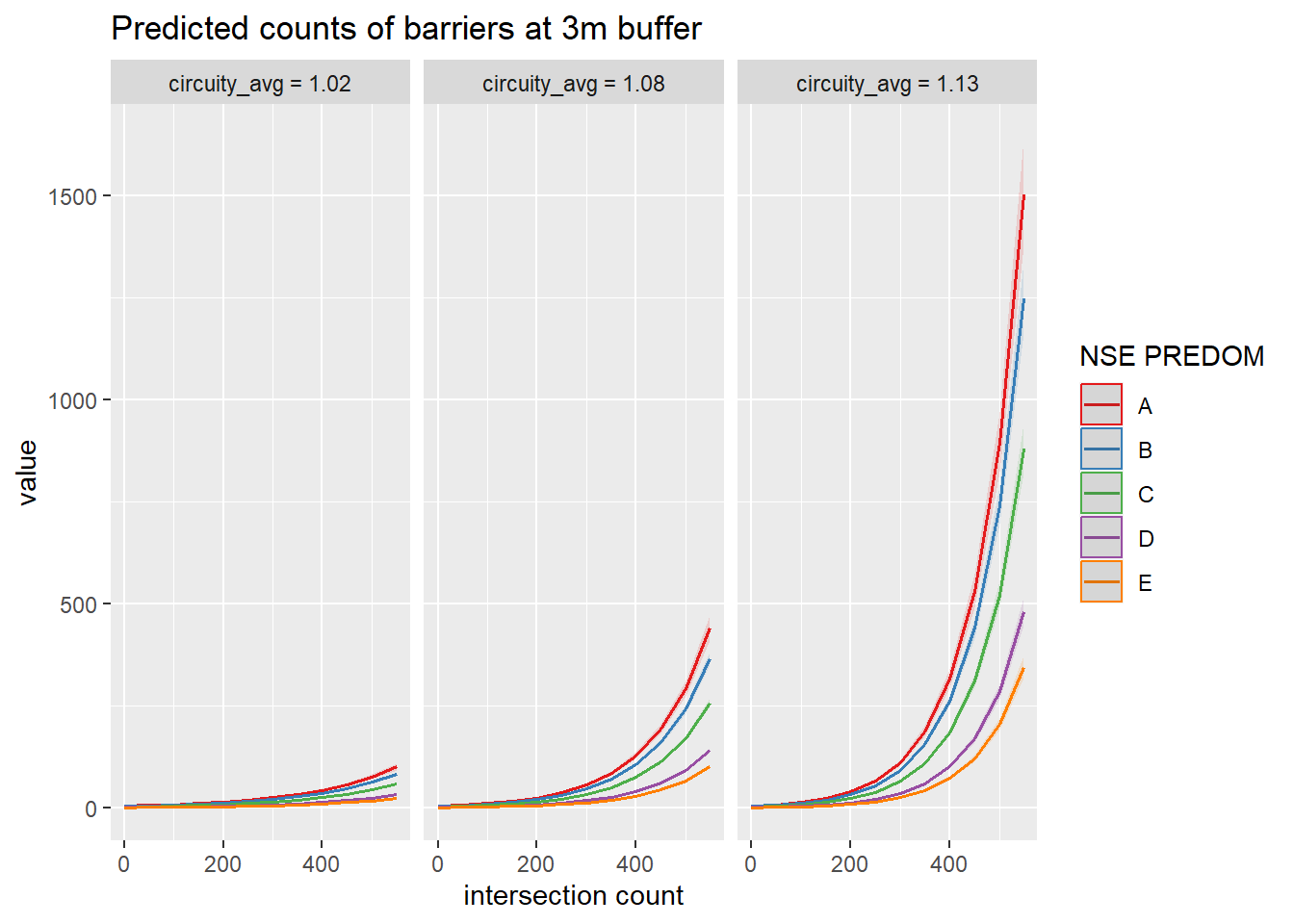
The overdispersion is present, suggesting the preferred choice is a negative binomial regression. With a distribution so heavily skewed, it helps to transform the variable to a log scale for visual purposes. Below, I plot the distribution of barriers at a 3m buffer and add the predominant SES in each block as a group. This allows to see that while higher SES blocks have more barriers around them, lower SES ones have several nonetheless.
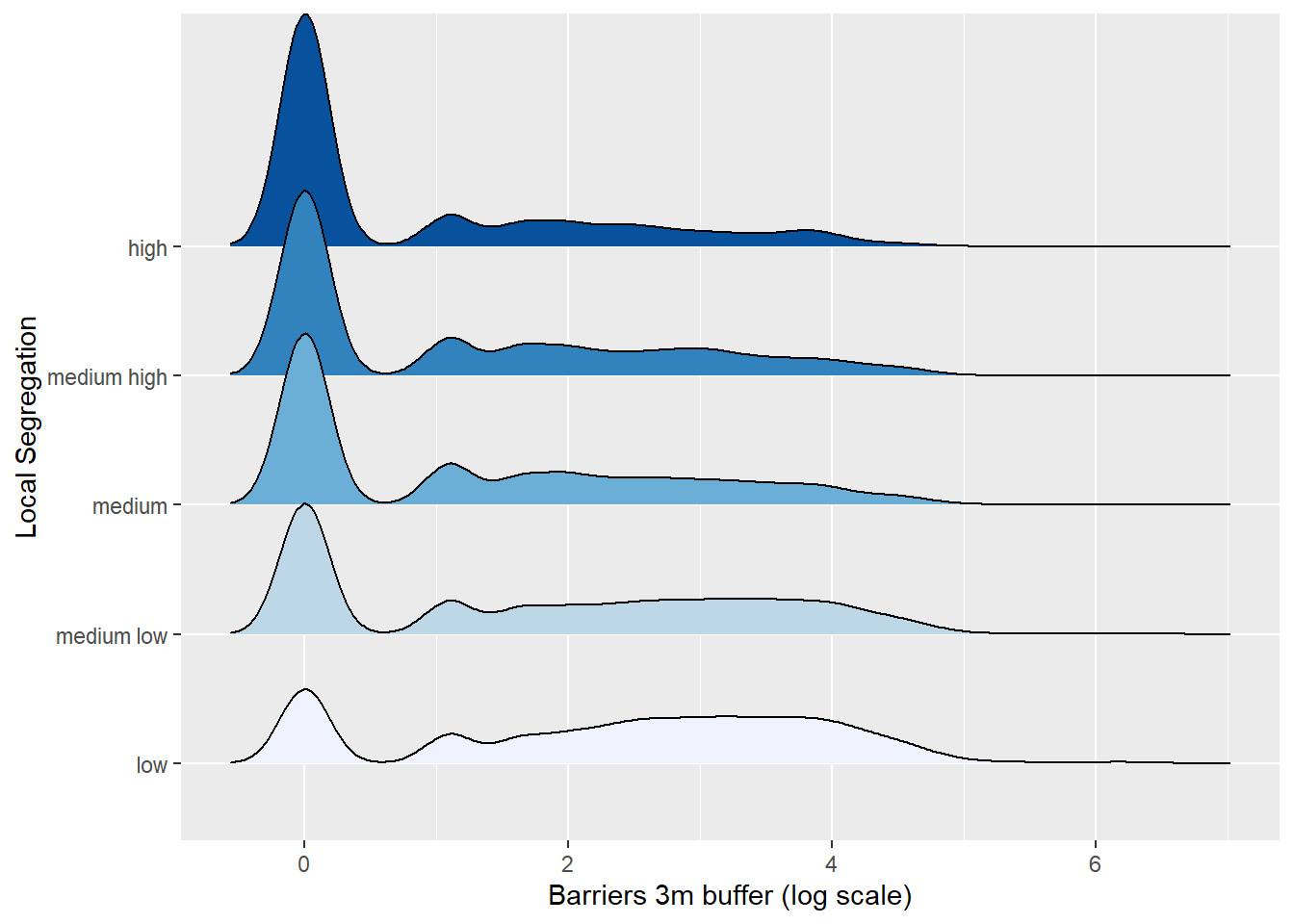
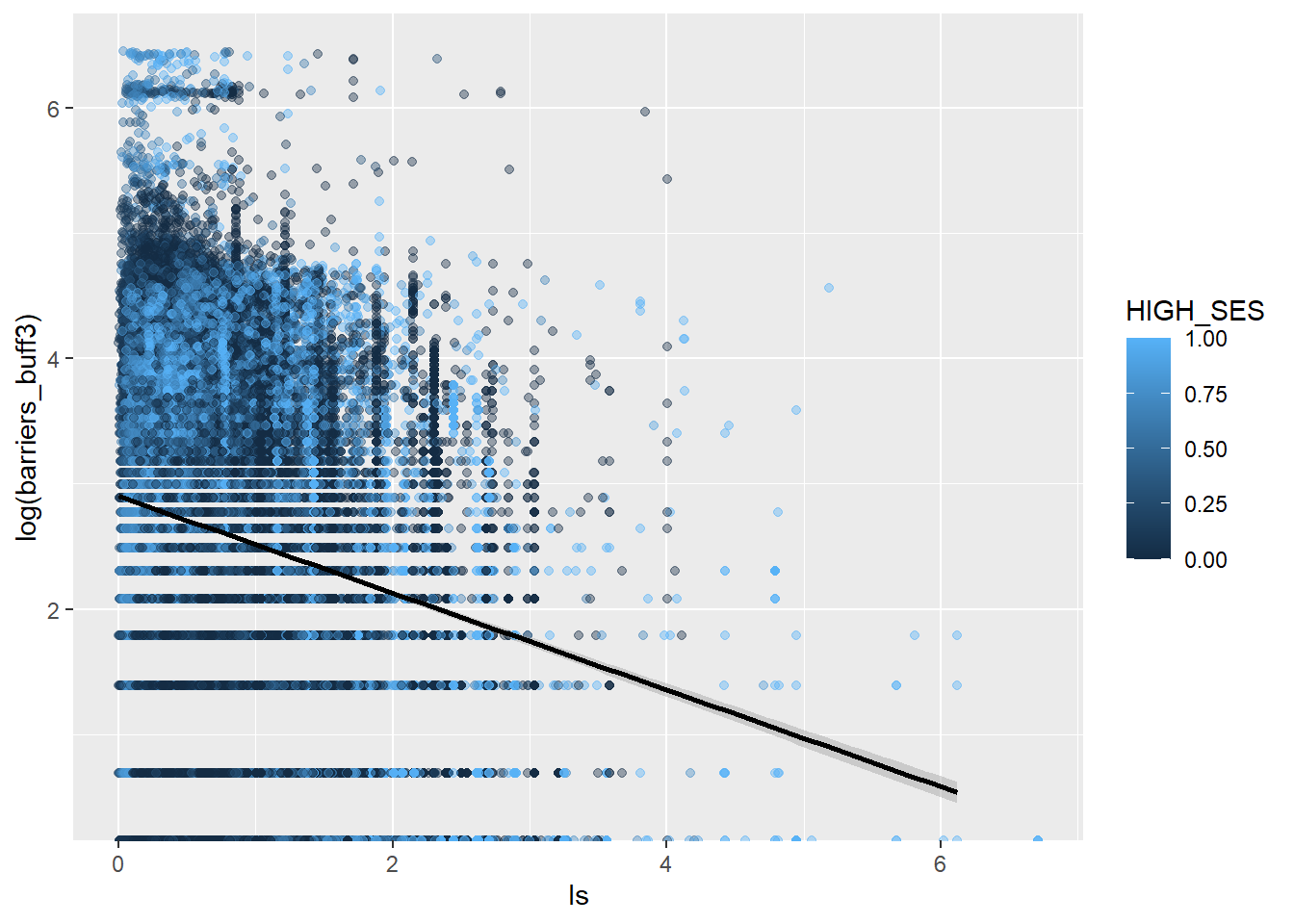
Besides SES, local segregation may be an important predictor of barriers. To test this before the model, we can take a visual look. The graph below shows that highly segregated places do not appear to have higher values of fences around them.
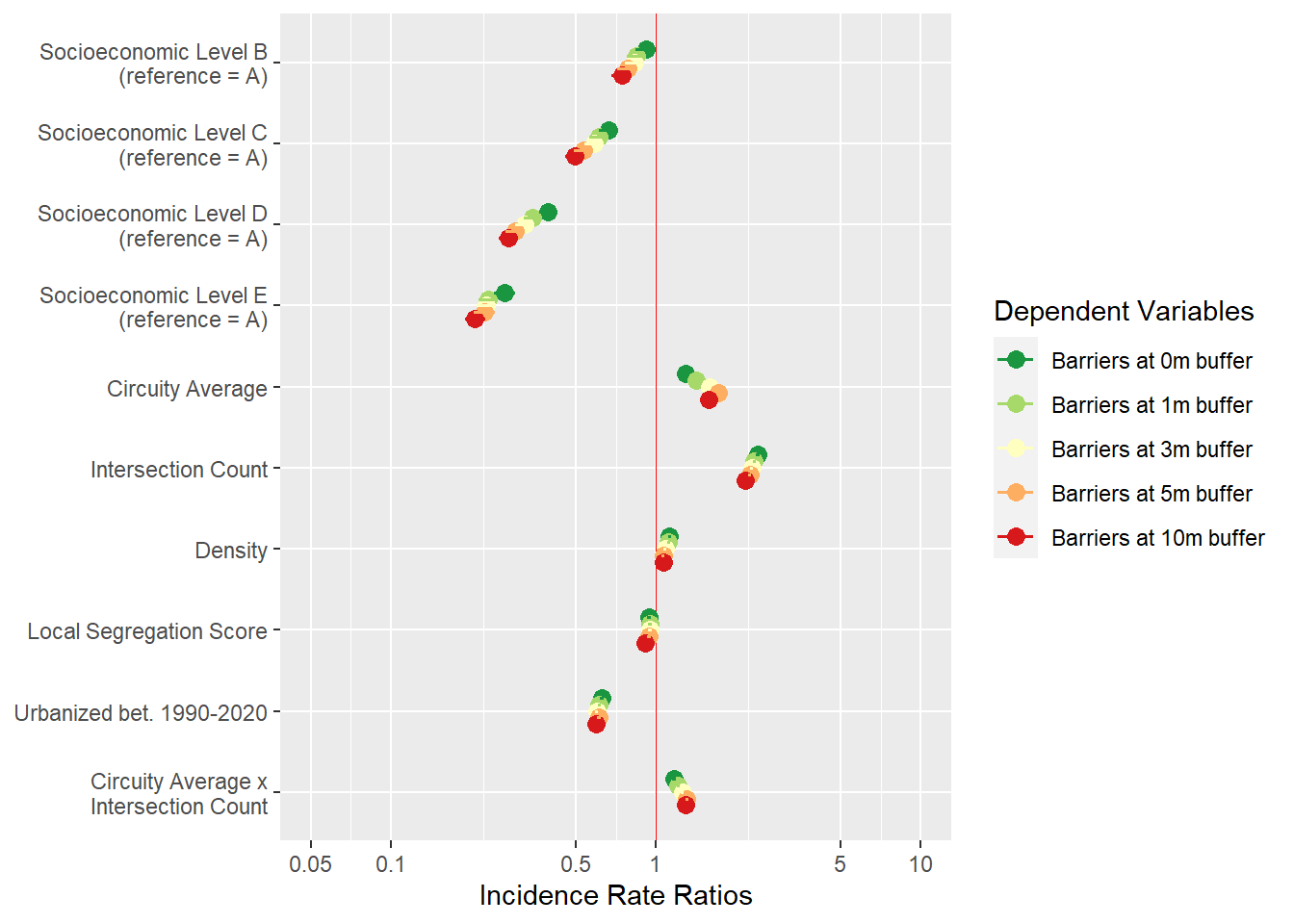
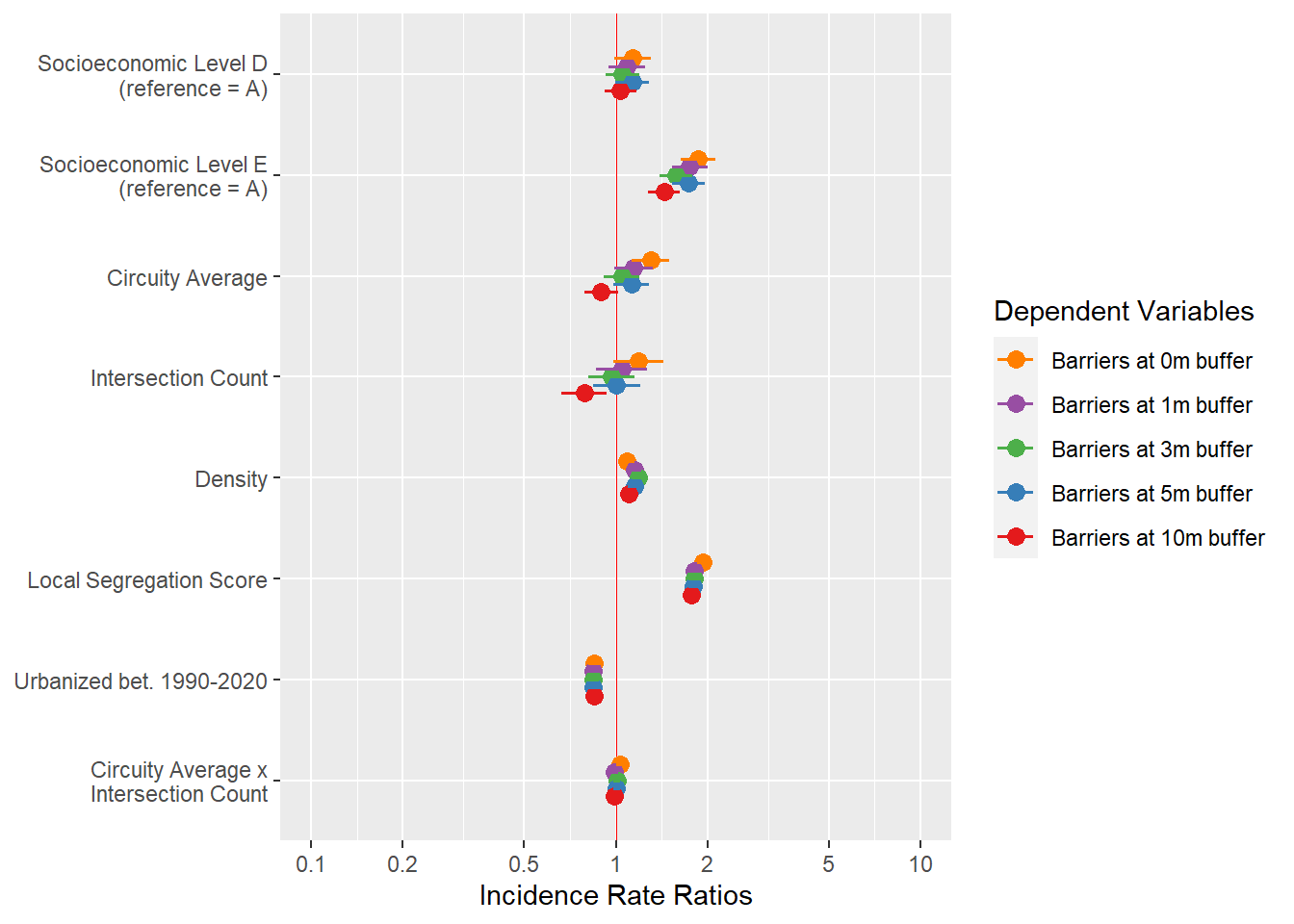
These are preliminary models. I have normalized the independent variables for interpretation. The models are negative binomial considering the distribution of the dependent variables and their overdispersion.
The models suggest that newer parts of the city have generally fewer fences. This may be part of the measurement bias.
There is evidence that higher SES have in general more fences around each block, but before I showed that lower SES blocks have several fences regardless of this difference. Also, note that local segregation scores (ls) comparing the block’s SES distribution with the district have no significant effect.
Not testing for spatial dependence since observations are exhaustive and, thus, not mutually independent.
The effect of urban design is clear in the effects of intersections and circuity average. More intersections are associated with more fences particularly when combined with more sinuous designs.
Models with restricted data
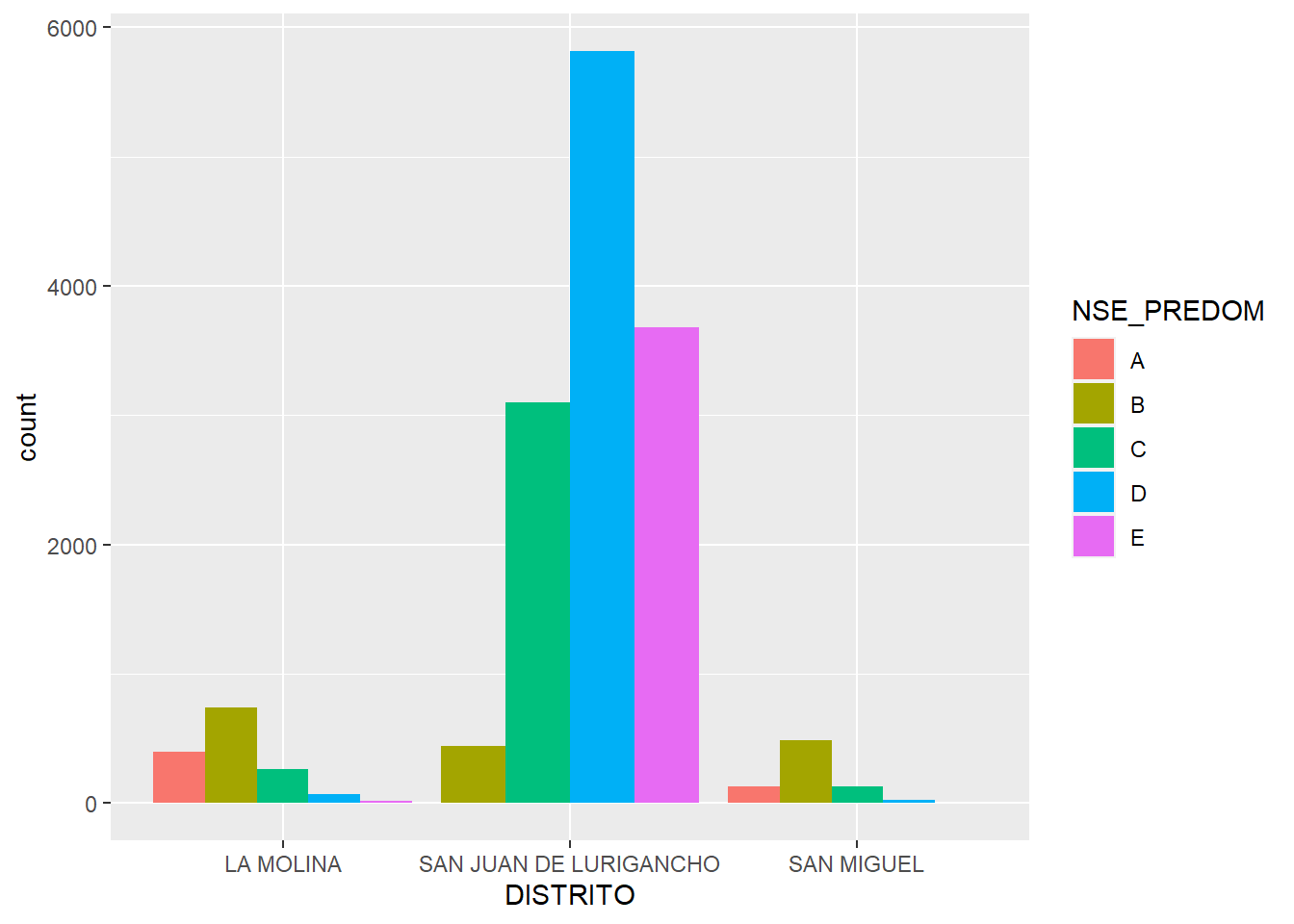
I start with some models for three districts: San Juan de Lurigancho, La Molina, and San Miguel. The first one is one of the largest in the city, with a population of over a million people. The data here is reliable as I contacted a person from that district to complete the data collection using Mapillary and he did most of the district. La Molina is relevant as a relatively new area of the city, developed largely after 1975, and with a high proportion of upper strata population. It is known for the proliferation of fences as well. The data is pretty good according to what Nelson and Christina (former RAs) commented. The third district, San Miguel, is a mostly middle-class one, for which the data is complete. This is where I started the data collection some time ago.
Code
selection =c('LA MOLINA', 'SAN JUAN DE LURIGANCHO','SAN MIGUEL')blocks_sample = blocks_data |>filter(DISTRITO %in% selection)blocks_sample |>ggplot(aes(DISTRITO, fill = NSE_PREDOM)) +geom_bar(position ='dodge')
In a way, the sampling here is of three districts with mostly reliable data and with different population and urbanization age profiles. La Molina is young, while San Miguel grew in the mid-1950s, and San Juan de Lurigancho in between the two.
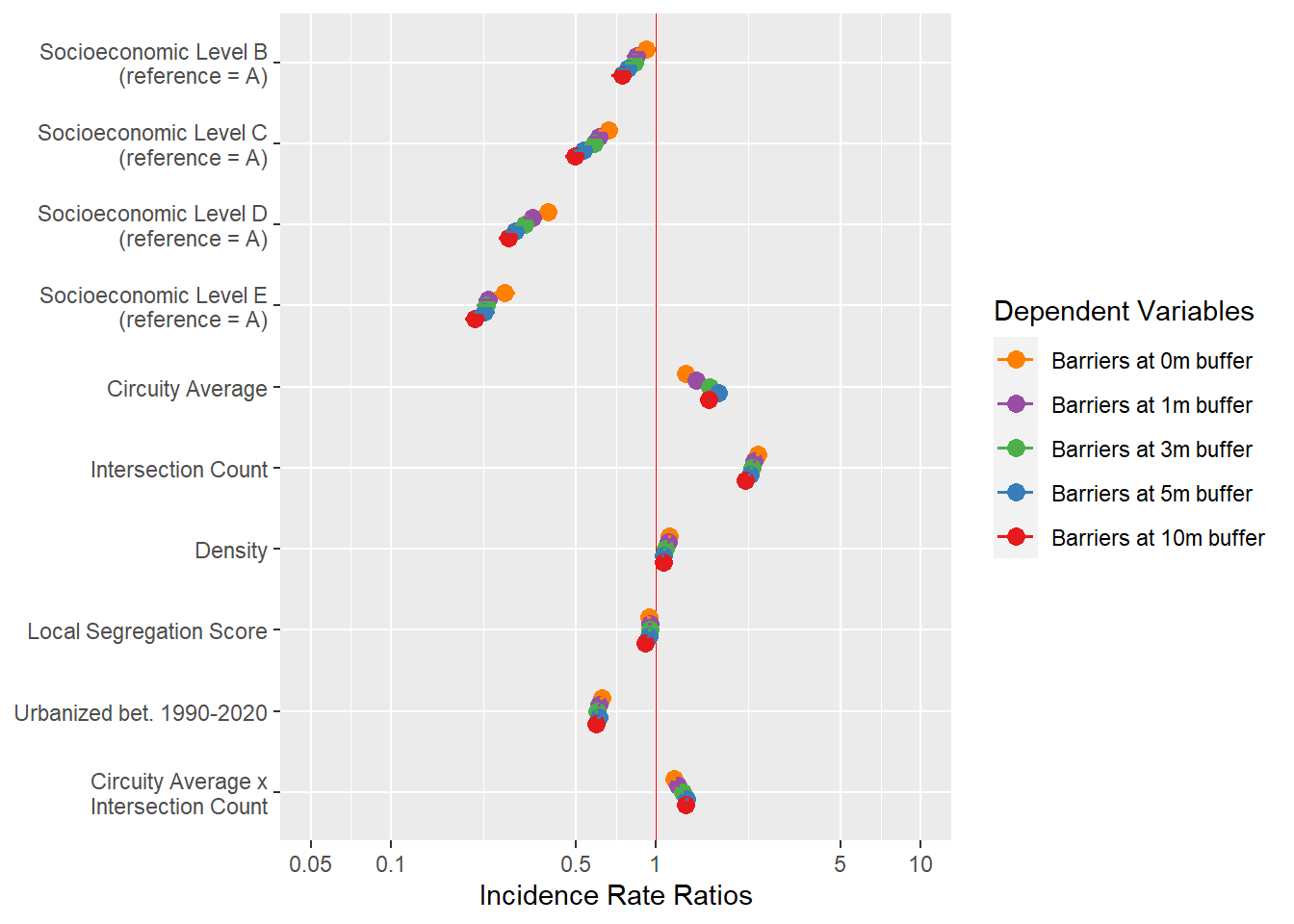
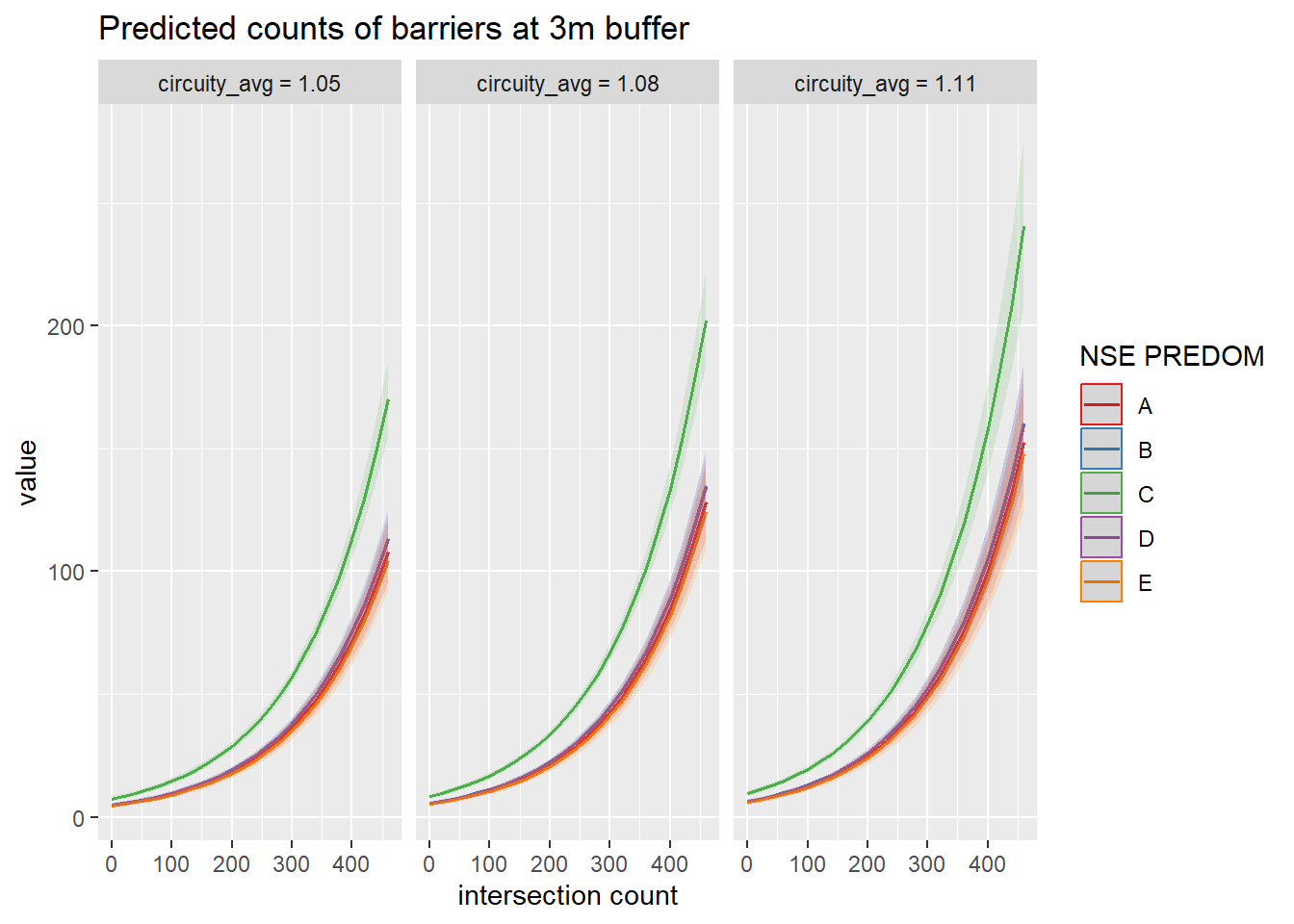
These models portray a very similar picture than the one for the full dataset. This suggests that the bias in the data may have not affected the results as much in the end.
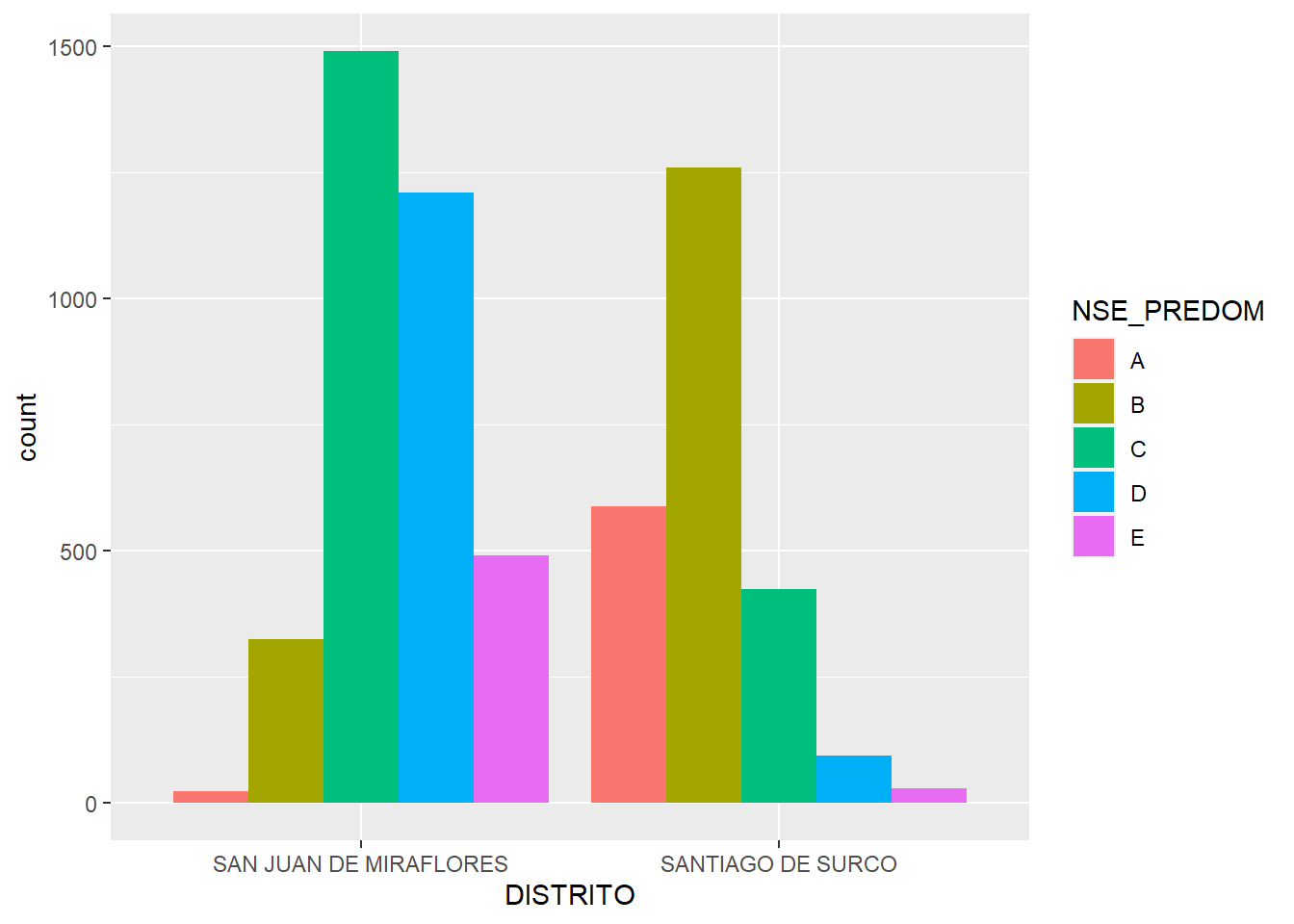
To confirm the trend, I tried to fit the regression using another sample of districts. The two districts are Santiago de Surco and San Juan de Miraflores. These are neighbouring districts in Southeast Lima. Both have several fences, and a population ranging across SES levels. Santiago de Surco has a larger population among the higher strata, while the opposite happens with San Juan de Miraflores.
Code
selection =c('SANTIAGO DE SURCO','SAN JUAN DE MIRAFLORES')blocks_sample = blocks_data |>filter(DISTRITO %in% selection)blocks_sample |>ggplot(aes(DISTRITO, fill = NSE_PREDOM)) +geom_bar(position ='dodge')
The results of the models here align more with my original hypothesis. There are no significant differences across SES levels, except that C-level blocks have more barriers around them.
In conclusion, the bigger dataset seems to be the way to go for the paper. I may add a commentary on the alternative sampling of districts, but not necessarily discuss it at large.